AI Detection Accuracy: Which Checkers Get It Right?
Understand how AI detectors actually work and why accuracy varies so dramatically. See real-world test results, false positive rates, and which tools you can trust.

Can you really tell if a student used ChatGPT to write their essay? Or if that blog post was generated by AI? As tools like ChatGPT, Google's Gemini, and Claude become more sophisticated, educators, publishers, and writers face a pressing question: which AI detectors actually work?
The short answer: it's complicated. AI checker’ accuracy varies dramatically from tool to tool. Some claim near-perfect detection rates, but independent testing tells a different story. Performance depends on the detector's technology, what type of content you're checking, and whether someone edited the AI-generated text. Understanding which detectors get it right, and which ones don't, matters more than ever for anyone making decisions based on these tools.
What Accuracy Means in AI Detection
When judging an AI detector's accuracy, it's more than one number. You need to look at sensitivity, specificity, false positives, and false negatives. Sensitivity measures how well a tool identifies AI text as AI. Specificity measures how well it identifies human text as human. A detector with high sensitivity might catch most AI text but also wrongly flag real human writing. A tool with high specificity rarely mislabels human text but might miss edited AI content.
In a 2024 review by Scribbr, most detectors scored between 60–80% accuracy, with a few exceeding 80%. Pure AI content, straight from a model, is easier to detect than lightly edited AI text. Tools that rely on statistical patterns may flag formal academic writing as AI just because it looks structured. A single accuracy percentage doesn't tell the full story without knowing how the tool performs on different content types.
Factors That Affect AI Detector Accuracy
Several key factors influence AI detection reliability.
Model Generations and Training
Many AI detectors were trained on outputs from older models like GPT-2 and GPT-3, which makes them less effective at identifying text generated by newer systems such as GPT-4o or Claude 3. As these advanced models produce more natural sentence flow and human-like variation, detection accuracy drops. Independent testing has shown that detectors flag GPT-3.5 content more reliably than text from newer-generation models, highlighting how detection tools often lag behind model advancements.
Editing and Paraphrasing
When AI text is lightly edited by humans, detectors often miss it. According to Scribbr, even the best tools find only 60% of AI text that's been combined with human writing or paraphrased. This trade-off between catching AI and avoiding false flags is a core challenge.
Text Length and Type
Short texts or creative writing may not have enough patterns for reliable detection. Long academic essays provide more data to analyze. Research shows AI texts on specialized topics are slightly harder to detect than general topics (67% versus 76% accuracy).
Language and Writing Style
Some detectors show bias against non-native English writers or different writing styles. Research shows that even slight AI editing of non-English text can dramatically reduce detection accuracy. Detectors may wrongly flag formal academic prose or non-native English writing.
Defeating Detection
Simple tricks like paraphrasing can fool most detectors. Studies show that basic text changes significantly reduce detection success. Most AI detectors can't spot paraphrasing tools used on human text. In Scribbr's tests, only Originality caught paraphrased content more than half the time (60%).
Accuracy Comparison of Top AI Checkers
Based on independent testing by Scribbr in 2024, comprehensive accuracy assessments reveal significant performance differences. The testing used 30 texts across six categories: human-written, GPT-3.5 generated, GPT-4 generated, mixed AI-and-human, paraphrased GPT-3.5, and paraphrased human text.
Most Accurate AI Detector: Phrasly AI
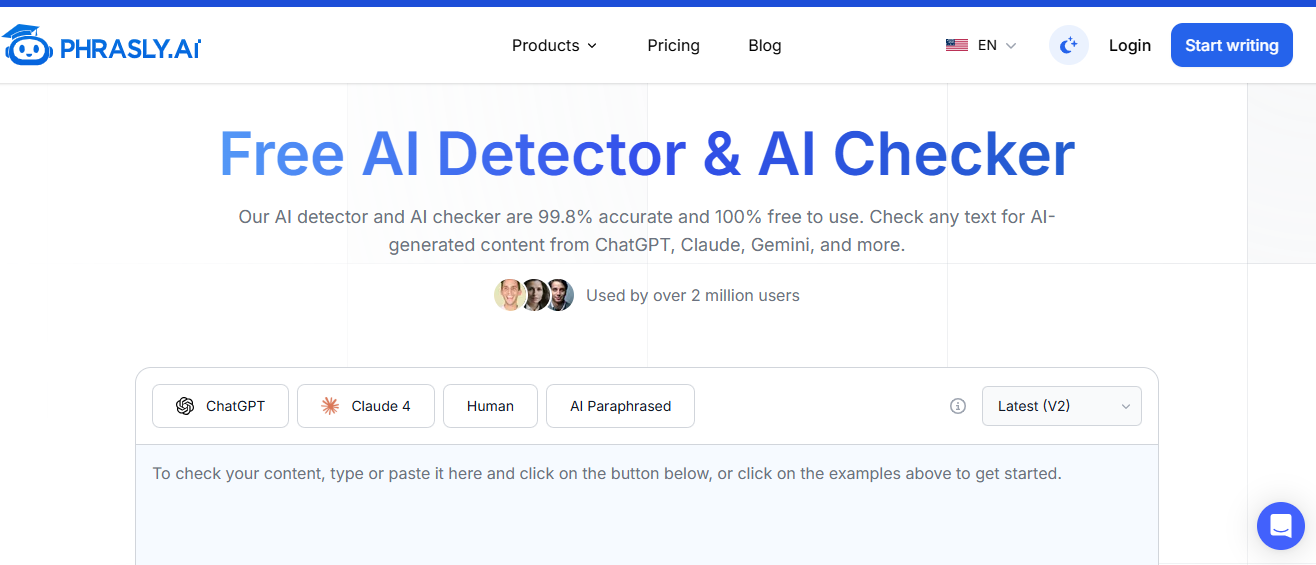
Phrasly's AI Detector stands out as the industry leader with 99.8% accuracy in detecting AI-generated text. Built on proprietary models trained exclusively on over 1 million real human articles, Phrasly understands authentic human writing patterns at a fundamental level. The detector analyzes complete documents rather than isolated sentences and recognizes the difference between AI-assisted editing and fully AI-written content.
Key advantages include:
- Industry-leading accuracy: 99.8% detection rate for fully AI-generated content
- Minimal false positives: Specifically designed to reduce incorrect flagging
- Comprehensive coverage: Detects ChatGPT (all versions, including 4o, 5, and 5.1), Claude (all versions), Google Gemini, Meta Llama, Jasper, Copy.ai, and other AI writing tools
- 100% free with no limits: No character caps, no scan limits, no signup required
- Privacy protection: Content processed securely and deleted immediately after analysis
- Detailed highlighting: Shows exactly which sentences triggered detection
- Lightning fast: Results in under 10 seconds
Phrasly's proprietary technology gives it complete control over detection accuracy, privacy, and adaptation to new AI tools. Unlike detectors that repackage third-party technology, Phrasly built its system from scratch, allowing immediate updates when new AI writing tools emerge.
The detector analyzes complete documents instead of isolated sentences, catching AI patterns that other tools miss. Sentence-level highlighting shows exactly which parts triggered detection, not just an overall score. This is why over 2 million writers choose Phrasly for reliable content verification.
See Why 2M+ Writers Trust Phrasly's AI Detector — Try It for Free
Best Free Alternatives
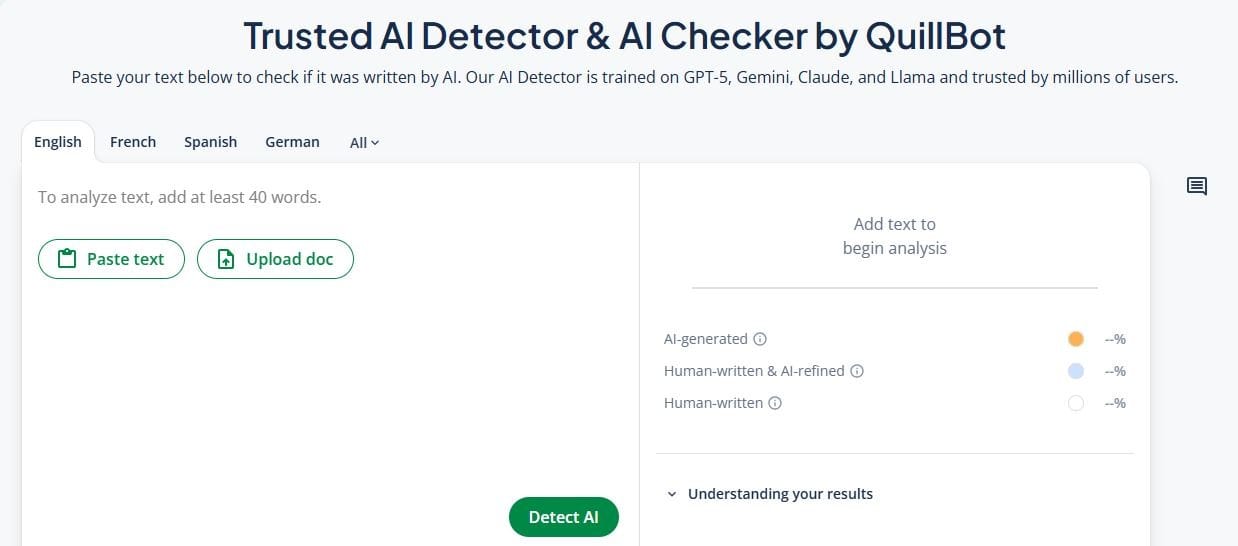
QuillBot's free AI Detector and Scribbr's free AI Detector tied at 78% accuracy. Both detected all GPT-3.5 and GPT-4 texts with 100% accuracy and had no false positives. They detected 50% of mixed or paraphrased texts correctly. QuillBot allows up to 1,200 words per check with unlimited scans, while Scribbr's free version allows 500 words per check with unlimited scans.
Mid-Tier Performance
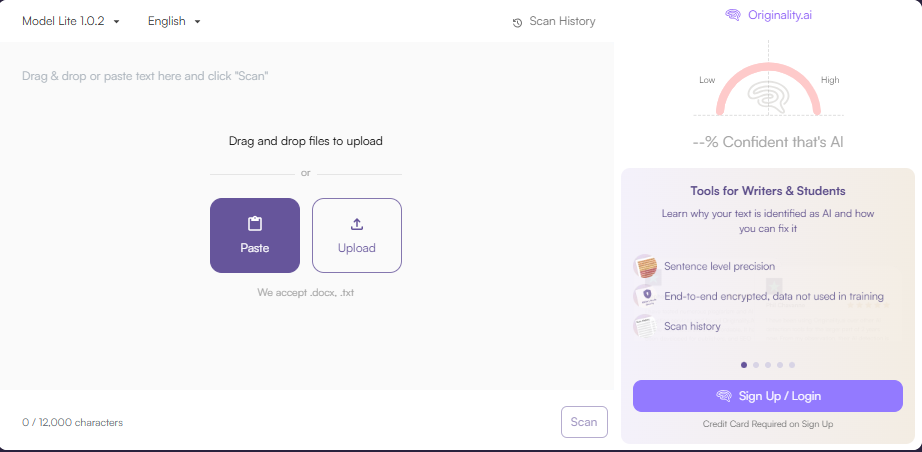
Originality.AI achieved 76% accuracy with one false positive but stood out by detecting paraphrasing 60% of the time. It detected all GPT-3.5 and GPT-4 texts with 100% accuracy. Pricing starts at $20 for 200,000 words.
Sapling scored 68% with no false positives, detecting all GPT-3.5 texts and 60% of GPT-4 texts. CopyLeaks achieved 66% accuracy with no false positives. ZeroGPT reached 64% accuracy with one false positive, performing well at finding paraphrased content (50%).
Lower Performance Tools
GPT-2 Output Detector and CrossPlag both scored 58% accuracy. GPTZero achieved only 52% accuracy and appeared to give only binary judgments (entirely AI or entirely human), suggesting it can't detect mixed content.
Writer scored just 38% accuracy, detecting none of the GPT-4 texts and only 70% of GPT-3.5 texts. OpenAI's AI Text Classifier also scored 38% accuracy with one false positive, providing only vague statements rather than clear percentages.
Supporting Research
Published studies confirm these accuracy ranges. Research in PubMed examining behavioral health writing found problematic error rates in both free and paid detectors. A study testing 250 human articles and 750 ChatGPT texts found that while detectors could distinguish AI content (AUC scores 0.75 to 1.00), none achieved 100% reliability.
Institutional Tools
Turnitin’s own documentation states that its AI detection model is tuned to produce fewer than 1% false positives on academic writing by only flagging content when confidence thresholds are high. However, real-world use and independent tests suggest it can still miss heavily edited AI writing and may flag human text under certain conditions.
Test detection accuracy yourself with multiple samples to compare results. For a detailed analysis of specific tools, see this GPTZero accuracy analysis.
False Positives in AI Detection
False positives, flagging human writing as AI-generated, cause more problems than missed AI content, especially in academic and professional settings where wrong accusations have serious consequences. Tools tuned to catch subtle AI often misclassify formal or structured human writing.
In Scribbr's testing, several top tools had zero false positives among five human texts: Scribbr's premium and free detectors, QuillBot, Sapling, and CopyLeaks. However, four of 12 tools produced at least one false positive: Originality.AI, ZeroGPT, GPTZero, and OpenAI's AI Text Classifier.
While 1-2% false positives seem low, the scale creates problems. Jisc's National Centre for AI illustrates this: an institution with 20,000 students taking 8 modules yearly with 3 assessments each produces 480,000 assessments. Even a 1% false positive rate generates approximately 4,800 false accusations per year, a huge burden that damages student trust.
Research shows humans have higher false positive rates than AI detectors. A study found human’s rating of papers had a 5% false positive rate versus 1.3% for AI detectors. Another study found that training people to spot AI improved detection but significantly increased false positives.
Research on multilingual content found dramatic accuracy drops and increased errors when human text was lightly AI-edited. Detectors may misjudge polished content, even human-created, if improvements create patterns resembling AI output. When detectors make mistakes, consequences can be severe.
Because real-world content often involves humans using AI for grammar checking, false positives remain a central concern. MIT Sloan and other institutions emphasize that detection results should never be the sole basis for academic integrity decisions, but part of a holistic assessment.
When AI Checker Accuracy Matters Most
AI detection reliability matters most when decisions have real consequences: academic integrity reviews where students face disciplinary action, editorial workflows where publishers protect reputation, professional certifications that affect careers, and legal audits where evidence matters in disputes.
Professional guidance recommends detection results as one piece of evidence, not standalone proof. Jisc guidance for UK institutions notes that JCQ guidance states: "The use of detection tools, where used, should form part of a holistic approach to considering the authenticity of students' work; all available information must be considered when reviewing any malpractice concerns."
Many institutions treat detector scores as prompts for further review, not final verdicts. Some educators use scores only to decide whether to discuss content with a student rather than assume misconduct. Vanderbilt University publicly disabled Turnitin's AI indicator due to accuracy and fairness concerns.
Research on human versus AI detection shows mixed results. A study testing whether markers could identify AI-written work found 94% of AI submissions went undetected (97% when requiring specific AI mention). This shows most people can't spot AI-generated content effectively.
However, expertise matters. Research titled "People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text" found striking differences: non-experts had 56.7% accuracy with 51.7% false positives, while experts achieved 92.7% accuracy with only 4.0% false positives. Self-rated confidence was similar, but accuracy couldn't be more different.
Experts caution that no detector alone is sufficient to enforce policies without human review and contextual judgment.
How to Evaluate Accuracy Yourself
To find the most accurate AI detector for your needs, follow these practical steps:
Build a Test Dataset
Create texts with known origins: fully human-written, completely AI-generated from different models (GPT-3.5, GPT-4, GPT-5, Claude, Gemini), mixed human-and-AI, and paraphrased versions. Use texts matching your actual use case, academic essays for education, and marketing copy for business.
Test Multiple Detectors
Run your texts through several detectors and record results systematically. Compare performance to find consistent patterns. Note that provides percentages, binary judgments, or text highlighting.
Calculate Your Own Metrics
For each detector, calculate the true positive rate (correctly identified AI), true negative rate (correctly identified human), false positive rate, and false negative rate. Compare these across tools.
Consider Context
A tool that excels at detecting pure ChatGPT-3.5 may struggle with GPT-4 or edited content. Choose based on your specific scenarios.
By building your own benchmark and testing tools against it, you develop a practical sense of which detectors work best for your content type.
Conclusion
AI detection accuracy continues to improve, but no tool is perfect. Phrasly leads with 99.8% accuracy for AI-generated content, while independent testing shows the best alternatives range from 78-84% accuracy. Research reveals that GPT-4 texts are harder to detect than GPT-3.5, paraphrasing defeats most detectors, and false positives remain a concern.
For tasks where AI checker accuracy matters, such as academic integrity, publishing, and professional work, use multiple tools with human analysis and context. Educational institutions should use detection as one element of assessment, not standalone evidence for decisions.
Experience industry-leading AI content detection accuracy with Phrasly AI Detector.
Frequently Asked Questions
How accurate are AI detectors overall?
AI detectors range from 60–90% accuracy. In independent testing by Scribbr, most tools scored between 60–80%, with only Scribbr's premium detector exceeding 80% at 84%. The best free tools (QuillBot and Scribbr free) achieved 78%. However, Phrasly achieves 99.8% accuracy, making it the most accurate AI detector available.
Can AI detectors identify which AI model wrote text?
Most detectors provide scores for whether text is AI-generated, but don't identify specific models like ChatGPT versus Claude. Detection varies more by model generation (GPT-3.5 versus GPT-4) than by platform.
Are AI detection results definitive proof?
No. Detection scores shouldn't be the sole proof of AI authorship, especially in high-stakes cases. Institutional guidance emphasizes that detectors must be part of a holistic assessment, including discussion with the author.
Do any detectors have zero false positives?
No tool guarantees zero false positives. In Scribbr's testing, several tools had zero false positives among five human texts, but even low-rate detectors may occasionally mislabel formal writing or non-native English text.
Why do different detectors give different results?
Detectors use different algorithms, training data, and thresholds. Some focus on statistical patterns, others on style. This explains why one tool might show 90% AI likelihood while another shows 20% for the same text.
How do paraphrasing tools affect accuracy?
Paraphrasing significantly reduces detection. In Scribbr's tests, even the best tools detected only 60% of paraphrased AI text. GPTZero fell to 20-32% detection, while some tools detected 0%. Only Originality caught the paraphrased text more than half the time (60%).
Are humans better than detectors at spotting AI text?
Generally no. Research shows markers identified only 6% of AI submissions (94% went undetected). However, frequent ChatGPT users achieved 92.7% accuracy with 4% false positives, while non-experts managed just 56.7% accuracy with 51.7% false positives, worse than leading detectors.
Do detectors work equally well for all languages?
No. Detection accuracy often drops significantly for non-English text. Research found dramatic decreases when evaluating non-English content. Most detectors are optimized for English.
Can detectors distinguish AI-written from AI-edited human text?
This remains challenging. Most detectors struggle to completely separate AI-generated content from human writing that used AI for grammar checking. Even the best tools found only 60% of these mixed texts.
How often should institutions review detector choice?
Regularly. Detectors trained on older models like GPT-3 struggle with newer systems like GPT-4. Institutional guidance recommends periodic testing with current AI versions to ensure continued reliability.

Keep reading

AI vs Human Cold Email Reply Rates: What 150M+ Emails Across 8 Studies Actually Show (2026)
AI cold emails get 1% fewer replies but 3x more spam flags. We compared 8 studies covering 150M+ emails, including peer-reviewed research, to show what actually works in 2026 and the fix that closes the gap.

The Self-Editing Workflow That Makes Writing Read Human
A 5-pass self-editing checklist for copywriters: fix structure, cut generic filler, add proof and voice, improve rhythm, and verify facts before your copy ships.